Groupe de travail Data
Responsables du Work Package : Violette Abergel, Dan Vodislav, Serge Cohen
![]()
![]()


![]()
![]()
Objectifs
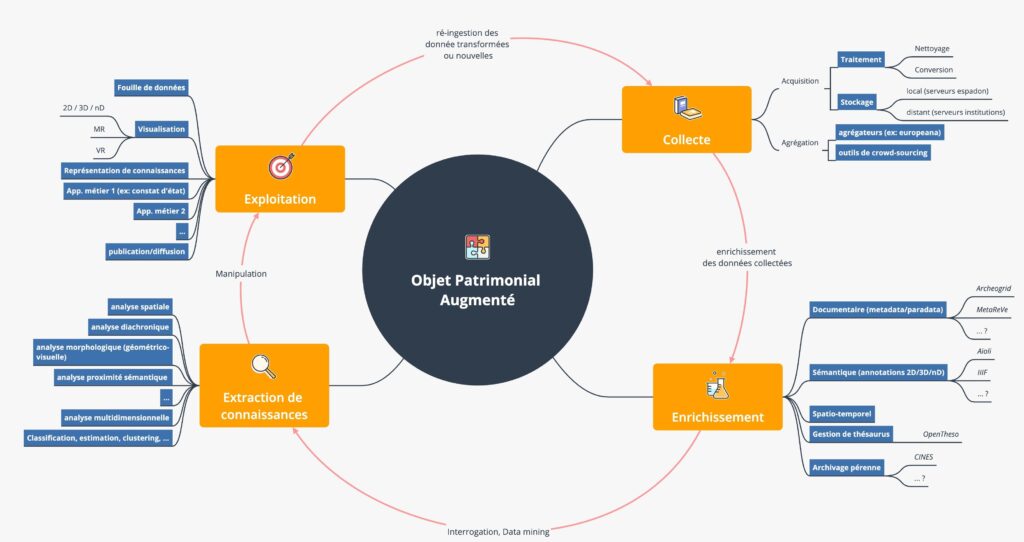
Le volet data d’ESPADON vise à améliorer la gestion, l’analyse, l’exploitation, et le partage des données du patrimoine. A travers la construction d’un écosystème numérique, il ambitionne d’instaurer un cercle vertueux au sein duquel des méthodes de gestion et de corrélation de données multidisciplinaires basées sur l’identification de relations sémantiques, spatiales, temporelles, ou de provenance, pourraient favoriser non seulement l’émergence de nouvelles connaissances sur les objets du patrimoine, mais aussi de nouveaux mécanismes de synergie entre les disciplines et communautés mobilisées dans leur étude. Cet écosystème est composé de plusieurs briques logicielles interopérables et articulées dans des parcours données/utilisateurs, visant à donner corps au concept d’Objet Patrimonial Augmenté.
Briques logicielles
Briques logicielles développées dans le cadre d’ESPADON
Briques logicielles provenant de projets fédérés financés par la FSP
Autres briques logicielles provenant de projets fédérés externes
Briques logicielles développées dans le cadre d’ESPADON
Constat d’état
Cette application web développée au sein du WP Data d’ESPADON permet de saisir des constats d’états conformément à la norme ISO 16245. Des fonctionnalités d’extraction semi-automatique permettent aux utilisateurs de récupérer rapidement des données à l’aide du numéro d’identification de l’œuvre étudiée depuis plusieurs plateformes (EROS, JOconde, Louvre). Les données ainsi renseignées peuvent être téléchargées en JSON ou en PDF.
Alignement Wikidata
Largement utilisée dans les domaines de la recherche, de la culture et du numérique, Wikidata est l’une des principales sources de données liées ouvertes, organisées sous la forme de graphe de connaissances. A travers une base de connaissances mondiale, ouverte et structurée, Wikidata répond à la demande croissante d’outils computationnels pour traiter efficacement l’information. Les données mises à disposition sur Wikidata sont sous une licence ouverte, en garantissant ainsi l’accès, l’exploitation, la modification et le partage libre. Le WP Data d’ESPADON a conçu une brique logicielle d’alignement des données avec Wikidata, afin d’assurer la conformité des données du patrimoine aux principes FAIR (faciles à trouver, accessibles, interopérables et réutilisables). De fait, relier des entités (personnes, lieux, œuvres, concepts…) à leurs identifiants Wikidata permet de bénéficier d’une interopérabilité immédiate avec d’autres bases de données, facilitant ainsi les échanges, la comparaison et l’enrichissement mutuel des informations. Cela améliore également la visibilité des données, qui deviennent accessibles via un écosystème international d’outils, d’API et d’applications. Cette brique constitue ainsi un pas important pour exploiter tout le potentiel du web sémantique et des technologies liées à l’IA, qui s’appuient fortement sur des identifiants et des données structurées fiables.
Utilitaire de renseignement d’échelle pour les données instrumentales
Cet outil vise à automatiser l’extraction de l’échelle dans les images issues de microscopie optique, habituellement renseignée de manière visuelle à travers des incrustations, afin d’en faciliter les traitements ultérieurs. Cet utilitaire utilise un algorithme d’analyse d’images permettant d’extraire le DPI de l’image, c’est-à-dire, le nombre de pixels distincts que l’on peut représenter sur une ligne d’un pouce (2,54cm).
Briques logicielles provenant de projets fédérés financés par la FSP
Anamnesis
Les instrumentations en sciences du patrimoine sont aussi nombreuses et variées que leurs modalités de mises en œuvre et que les techniques mobilisées. Dès la collecte des données brutes, de nombreux choix sont opérés pour s’assurer d’adapter l’instrumentation aux enjeux documentaires et analytiques propres à chaque projet. Cette étape marque la genèse d’un flux de données numériques, généralement non-structurées et multiformes, qui passent par des traitements et diverses transformations jusqu’à leur stockage ou archivage pérenne. En outre, le défi de l’ouverture des données selon les principes FAIR impose un enrichissement contextuel de ces données par le biais de champs de métadonnées. Sans anticipation de cette contrainte, cette documentation a posteriori des métadonnées peut s’avérer laborieuse, chronophage et imprécise.
Financé dans le cadre de l’appel à projet 2024 de la FSP et porté par Anthony Pamart, ce projet ambitionne de répondre à cet enjeu, afin d’aborder la documentation des informations liées à la provenance et à la traçabilité des données instrumentales le plus en amont possible des chaînes de production de données. Anamnesis propose de développer un prototype matériel et logiciel permettant d’encoder les métadonnées et paradonnées essentielles pour le lignage des données. La partie logicielle de ce système est déployée au sein de l’écosystème Espadon, et propose, à travers une interface conviviale et adaptée aux nombreuses facettes et contraintes des données patrimoniales, des fonctionnalités permettant de générer des schémas de métadonnées et de paradonnées, ainsi que différents outils dédiés à leur saisie.
Metareve
Pour les sciences du patrimoine, les enjeux de gestion de données numériques se trouvent aujourd’hui confrontés à la forte hétérogénéité de sources documentaires (textes, images, vidéos, …), de données analytiques (issues de divers capteurs, techniques d’imagerie, analyses d’échantillons, …) et de processus de traitement mobilisés à des fins de description, analyse, suivi, ou encore conservation. Garantes de la fiabilité d’une donnée, les métadonnées et paradonnées de provenance fournissent des renseignements précieux pour rendre compte des contextes d’acquisition et des possibilités de réutilisation ultérieures. Dans ce contexte, le projet METAREVE, financé par la FSP dans le cadre de son appel à projet 2023 et porté par Violette Abergel, propose de simplifier cette démarche en l’accompagnant depuis la production des données sur le terrain jusqu’à leur traitement ex situ. La méthode innovante proposée vise à automatiser l’extraction de ces informations à l’aide d’approches de compréhension automatique de la parole (ASR) et de traitement automatique des langues (NLP) empruntées au domaine de l’intelligence artificielle, en s’appuyant pour cela sur des thésaurus construits par les différentes communautés mobilisées dans les sciences du patrimoine. Déployée au sein de l’écosystème numérique d’ESPADON à travers une API RESTful, METAREVE permet d’automatiser l’extraction de métadonnées, garantissant ainsi une documentation minimale des données collectées et la possibilité de les interroger de manière simple et intuitive.
Autres briques logicielles provenant de projets fédérés externes
Opentheso
Les données numériques occupent une place majeure dans les protocoles de recherche en sciences du patrimoine, qui se manifeste par une production quotidienne de données variées dont l’exploitation présente un grand potentiel en termes d’analyse scientifique. Toutefois, l’indexation et l’ouverture de données massives soulignent aujourd’hui le besoin de référentiels et de vocabulaires professionnels partagés, documentés et structurés. Opentheso vise à répondre à ces besoins, à travers un outil dédié à la gestion de thésaurus multilingues et multi-hiérarchiques. Initialement créé à la demande de la Fédération et ressources sur l’Antiquité (GDS Frantiq) pour la gestion du thésaurus Pactols, il est aujourd’hui diffusé en open-source sous licence CeCILL_C, Licence libre de droit français compatible avec la licence GNU GPL. Il est développé sous la direction de Miled Rousset au sein de la Maison de l’Orient et de la Méditerranée (MOM). Opentheso s’adresse ainsi à tous les professionnels susceptibles de produire, décrire, analyser et gérer des données scientifiques et des publications (chercheurs, ingénieurs, bibliothécaires, éditeurs, archivistes, documentalistes, conservateurs, …), en proposant différents outils pour la gestion et la curation de vocabulaires, la cartographie conceptuelle, l’attribution d’identifiants pérennes (Handle, Ark) et la création de lexiques structurés.
Aioli
Les archéologues, architectes, ingénieurs, spécialistes des matériaux, enseignants, conservateurs et restaurateurs de biens culturels contribuent quotidiennement à la connaissance et à la conservation des objets patrimoniaux. Depuis de nombreuses années, le développement des technologies numériques a donné lieu à des avancées majeures en matière de collecte, de visualisation et d’indexation des ressources numériques. Si ces progrès ont permis l’introduction de nouveaux outils faisant évoluer les pratiques de documentation au sein des communautés des sciences du patrimoine, la gestion de données multidimensionnelles et multiformats pose toutefois de nouveaux problèmes et défis, notamment en ce qui concerne le développement de méthodes d’analyse et d’interprétation pertinentes, le partage et la corrélation de données hétérogènes entre plusieurs acteurs et contextes, et l’archivage centralisé des résultats de la documentation à des fins de conservation à long terme. Malgré leurs approches et leurs outils d’observation, de description et d’analyse différents, les acteurs de la documentation du patrimoine culturel ont tous un intérêt commun et un objectif central : l’objet patrimonial, physique, qu’il s’agisse d’un site, d’un bâtiment, d’une sculpture, d’un tableau, d’une œuvre d’art ou d’un fragment archéologique. C’est le point de départ du développement d’Aïoli, une plateforme d’annotation sémantique 2D/3D développée au sein du MAP (UPR2002 CNRS).
Aïoli offre à chaque acteur du patrimoine la possibilité d’annoter et enrichir directement des représentations de ses objet d’étude de manière collaborative, créant un pont entre les objets du patrimoine et les connaissances produites par différentes communautés impliquées dans leur étude.
IIPImage
IIPImage est un serveur d’images performant et riche en fonctionnalités, conçu pour la visualisation et le zoom en flux continu d’images ultra haute résolution via le web. Rapide et économe en bande passante, il requiert peu de ressources processeur et mémoire. Particulièrement utile pour répondre aux enjeux liés à la visualisation des données résultant de diverses techniques d’imagerie scientifique (images multispectrales, cartes numériques d’élévation, …), le système gère aisément les images de plusieurs gigapixels ainsi que les caractéristiques avancées telles que les images 8, 16 et 32 bits par canal, les images colorimétriques CIELAB. Le flux est organisé par tuiles, permettant ainsi de visualiser, naviguer et zoomer en temps réel sur des images de plusieurs gigapixels, impossibles à télécharger et à manipuler localement. Cette organisation confère également au système une grande évolutivité, le nombre de tuiles téléchargées restant constant quelle que soit la taille de l’image source. Les images sources peuvent être au format TIFF ou JPEG2000. Le serveur peut également redimensionner et exporter rapidement et dynamiquement des images entières ou des zones spécifiques à l’intérieur d’une image source unique, sans qu’il soit nécessaire de stocker plusieurs fichiers de tailles différentes.
Archeogrid
ArcheoGRID est un outil collaboratif permettant d’assurer la gestion de la documentation des projets en humanités numériques (iconographie, relevés, 3D, textes, données multimédia, …). Créé par Sarah Tournon-Valiente au sein d’Archeovision – Université Bordeaux Montaigne, Archeogrid offre de nombreuses fonctionnalités visant à répondre aux nombreux enjeux relatifs à la gestion de corpus de données hétérogènes annotation, indexation, préservation, sauvegarde, dissémination. ArcheoGRID permet notamment d’intégrer des données sémantiques aux données numériques afin d’être en mesure d’échanger ces informations selon les protocoles standards d’échange en vigueur (OAI-PMH, RDFa, DublinCore) et participer pleinement à l’ouverture des données de la recherche. ArcheoGRID comprend également des fonctionnalités permettant de visualiser les données, que ce soit individuellement ou sous forme de collections.
Ontoportal
OntoPortal est une plateforme web dédiée à la gestion, à la publication et à la visualisation d’ontologies. Elle permet de structurer, d’explorer et de partager des connaissances à travers des modèles formels qui définissent des concepts, des relations et des règles au sein d’un domaine particulier. Conçu pour faciliter l’interopérabilité entre différentes sources de données, OntoPortal permet aux utilisateurs d’explorer des ontologies complexes, de suivre l’évolution de leurs versions et de publier des contenus sur le web, tout en assurant la traçabilité des modifications. Il offre ainsi une interface interactive pour naviguer entre les concepts et les relations, tout en favorisant l’intégration de données provenant de multiples domaines. Dans le cadre d’ESPADON, cet outil offre non seulement une gestion fine des référentiels conceptuels, mais aussi une réponse à des enjeux de gouvernance de terminologies spécialisées, à travers la possibilité de versionner, partager et d’interroger les thésaurus provenant d’Opentheso.
Quasimodo
Développé dans le cadre du projet ERC n-Dame_Heritage (UPR 2002 MAP), Quasi.modo se présente comme une architecture conceptuelle et technique dédiée à l’exploration, l’intégration et l’interopérabilité des données et des connaissances produites autour d’objets patrimoniaux complexes. Son nom est un acronyme de “Querying and Unifying Architecture for Semantic Integration of Multidimensional Orchestrated Disciplinary Observations“, exprimant à la fois sa fonction — interroger, unifier et structurer — et son ambition : articuler des observations disciplinaires multiples dans une logique de convergence sémantique.
Le point séparant Quasi et modo est intentionnel : il marque une articulation critique. Il symbolise à la fois un connecteur fonctionnel et une modularité intellectuelle entre une approche ouverte, évolutive (quasi, “presque”, “en formation”) et une structure méthodique (modo, “manière”, “mode”). Cette ponctuation reflète la nature du projet : un espace interstitiel —ni rigide ni strictement normatif— mais orchestré pour permettre la coexistence raisonnée de logiques disciplinaires parfois hétérogènes.
La référence implicite à Quasimodo, le personnage emblématique du roman de Victor Hugo Notre-Dame de Paris, fait référence au personnage marginal et central, physiquement déformé mais profondément humain, gardien de la cathédrale et témoin silencieux de son histoire. Il incarne une forme de connaissance sensible, située au-dessus, entre le visible et l’invisible. De même, quasi.modo aspire à être un gardien numérique des données scientifiques liées à Notre-Dame et à d’autres sites patrimoniaux, capable d’embrasser la complexité de leur documentation multidisciplinaire tout en préservant la singularité de chaque regard savant.
Enraciné dans le travail scientifique mené autour de la restauration de Notre-Dame de Paris, le projet quasi.modo cherche à permettre une intégration sémantique n-dimensionnelle —spatiale, temporelle, morphologique, lexicale et méthodologique. Il offre un cadre unifié mais flexible, où les données de numérisation 3D, annotations, archives, analyses scientifiques et récits peuvent être explorées, liées et interrogées en utilisant des protocoles de recherche rigoureux, documentés et adaptables.
Quasi.modo n’est ni juste un acronyme ni simplement une plateforme logicielle. C’est un système de médiation des connaissances, un pont entre les disciplines, un observatoire augmenté des pratiques scientifiques et professionnelles — faisant écho au personnage dont il évoque le nom, et au monument dont il hérite la mémoire.
L’équipe